Best Web Scraping API 2026: Ranked by Real Benchmark Data
Web scraping API services are becoming very popular as the demand for web data is sky-rocketing. So, which web scraping API is the best and how to choose the right one?
In this article, we'll explore the three primary metrics used by Scrapeway to determine the most performant web scraping API:
- Success rate - how likely a service is to successfully return page content.
- Speed - how fast scraping is being performed.
- Price - the overall price of the service.
Start with real benchmarks
The only reliable way to evaluate web scraping services is to actually measure them.
As a reference, we'll use Scrapeways bi-weekly web scraping API benchmarks that evaluate for these 3 metrics. Here are example results for June 2024:
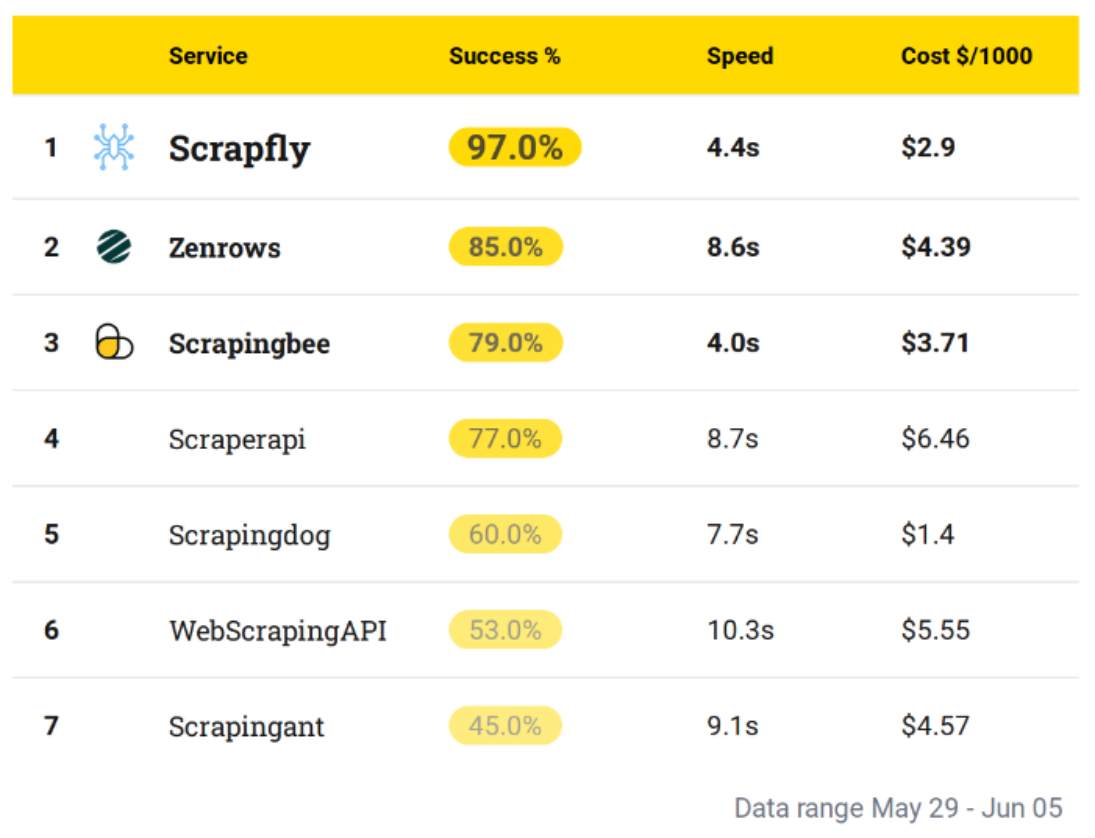
The above example represent an average performance of all web scraping targets covered by Scrapeway.
Stability & success rate
The primary goal of every web scraping service is to extract web data at scale successfully. This means that scraping APIs have to overcome web scraping blocking to be effective tools at scale.
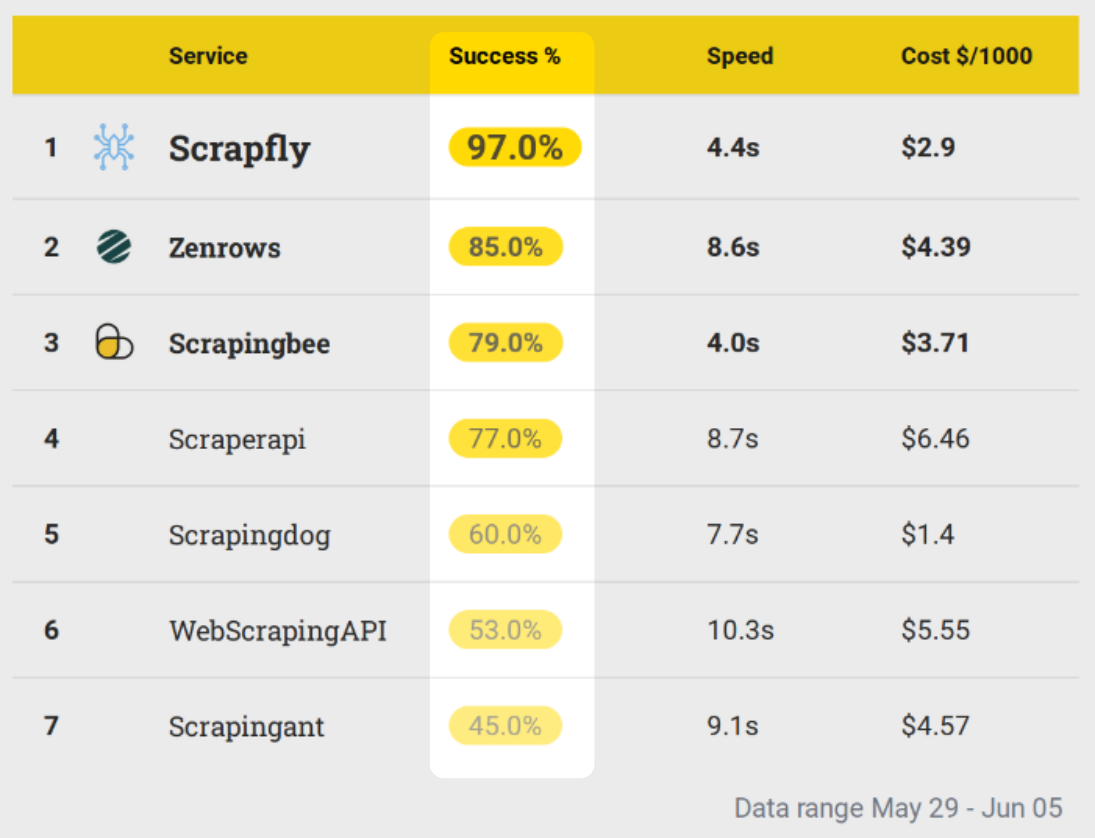
We see that this week has the highest success rate with and following closely behind when it comes to average success rate.
The success rate indicates the percentage of requests that succeed and when evaluating web scraping APIs we want this number as high as possible as it indicates:
-
Service technical capability
As anti-bot bypass is the toughest problem in scraping having a reliable anti-bot bypass is very important. Getting stranded with no more data supply for days is a nightmare for any data-driven business.
-
Service stability
For large continuous scraping projects it's important to have reliable and predictable service.
-
Cost reduction
Success rate directly translates to cost reduction as it decreases retrying and increases overall scraping performance.
Three types of failures can be encountered when using web scraping APIs:
- Websites use Anti-bot tools that block the scraper.
- Service encounters technical difficulties when scraping a specific page.
- Page is not scrapable because of user error.
Various Anti-bot systems is by far the most common reason why web scraping fails and in our benchmarks, it represents over 95% of all failures.
Service outages/bugs are much more rare with the top web scraping APIs we've tested and are usually resolved quickly representing the rest 5% of all failures.
As for user errors, these are harder to measure as this data is only available to web scraping API providers.
The primary cause of this issue is that some pages require headers or cookies to be set correctly for a successful scrape. Ideally, web scraping services could adjust requests automatically but we hadn't seen any features like this except for:
- WebScrapingAPI and ScrapingDog report suggestions for optimal API parameters though not scraping configuration like headers.
- Scrapfly's "ASP" feature can modify some headers, cookies and browser fingerprints.
Overall, we think that success rate is by far the most important metric when it comes to evaluating web scraping APIs and the entire reason we've founded Scrapeway benchmarks. Though other metrics are important too.
Speed
Speed is an essential metric to assess when looking for the best API for real-time web scraping.
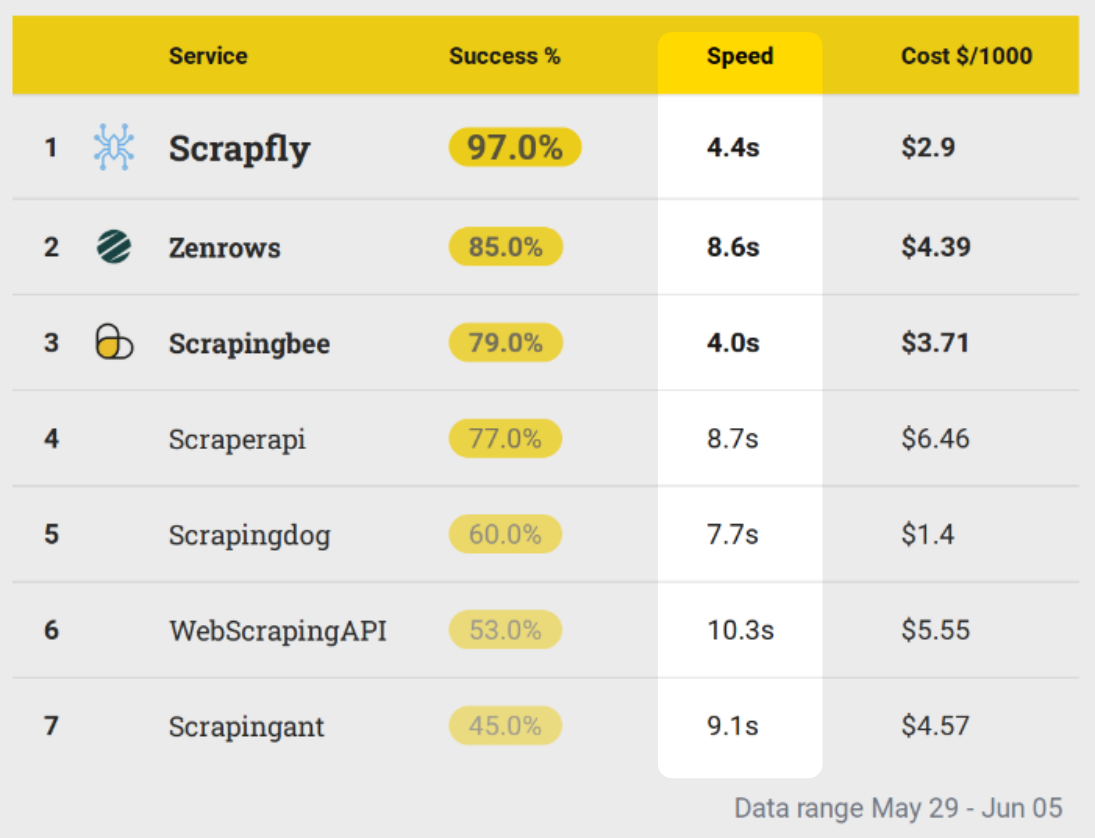
In our benchmarks, we see that and are the fastest in 4s average scrape time making these services more favorable for real-time web scraping applications.
Real-time web scrapers are usually integrated with real-time processes like web apps or data retrieval on demand systems. It's a small niche of the overall web scraping market but here every second counts.
For optimal speed performance consider these factors:
-
Avoid using the headless browser feature.
All web scraping APIs offer scraping using headless browsers however we found that this often slows down the scraping process significantly, often 3-10x!
-
Aim for a high success rate.
Failed requests need to be retried which means double or even triple the scrape time.
These two are by far the biggest factors that affect web scraping speed. Though, service stability and geographical location can also have minor impacts on overall speed performance.
Overall, speed is an important metric to consider when evaluating real-time web scraping APIs as for data collecting scrapers the more important metric is often the concurrency limit which varies by service and plan from 5 to infinity.
If you're unfamiliar with concurrency limits, it's the number of requests that can be sent at the same time. This can be a bottleneck of how quickly the full dataset can be collected but given the average 5-10 second scraping speed avg. concurrency of 10 can generate 60-120 scrapes per minute. This is often enough for most scrapers but worth considering nevertheless.
Price
Price is the final metric of the evaluation process though unlike success rate and speed, it's significantly less technical.
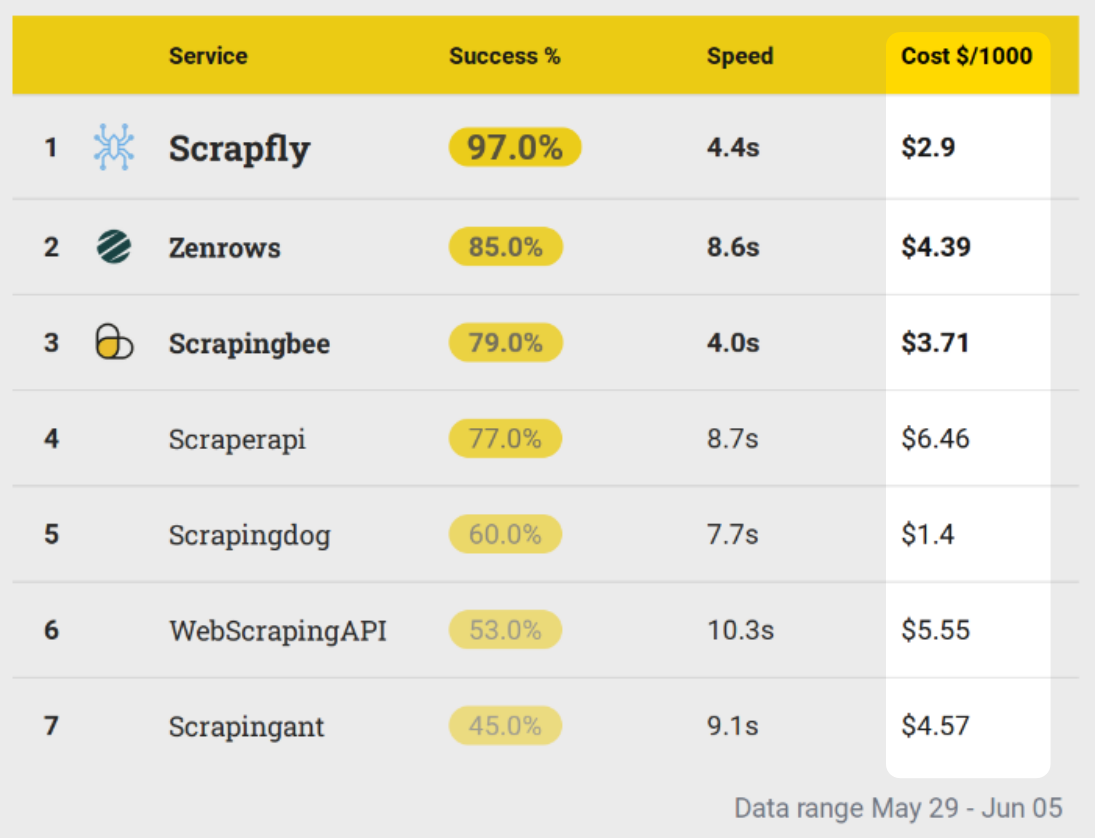
In this benchmark, we see that is clearly leading the average price though with a significantly lower success rate than and which are in a similar price range.
Most web scraping services follow the API credit-based model. Here each user subscribes to a monthly plan that gives X amount of credits to spend for the month.
The most important evaluation axis here is the credit cost of additional features. For example here are some features that often cost extra:
- Enabling of better proxies.
- Anti-bot bypass.
- Bandwidth consumed.
- Headless browser usage.
- Screenshot capture.
In our benchmarks, we represent pricing as bare-minumum spending required for scraping a single page and avoiding as many of these optional features as possible to reduce the costs.
Generally, all web scraping services have a similar pricing model where bare scrape request costs 1 credit and extra features cost extra credits:
- Headless browser is usually +5 to +10 credits
- High quality or residential proxies vary between +10 to +25 credits
This pricing model of "pay for what you use" is very convenient and provides a lot of space for budget optimization.
The biggest effect on overall price is the success rate as some services require extra features to be enabled like headless browsers or premium proxies to scrape successfully.
Another important metric to evaluate is entry point price. Some services like ScrapingAnt start as low as $19/month while others like Zenrows require a hefty investment of $69/month as a minimum. Here's a quick summary:
| Service | min usd/month | |
|---|---|---|
| 1 | ScrapingAnt | 19 |
| 2 | ScrapFly | 30 |
| 3 | ScrapingDog | 40 |
| 4 | ScraperAPI | 49 |
| 5 | ScrapingBee | 49 |
| 6 | WebScrapingAPI | 49 |
| 7 | Zenrows | 69 |
| 7 | Firecrawl | 19 |
Note that credits do not carry over month-to-month making this minimum commitment a very important pricing metric.
Finally, the pricing can fluctuate wildly every week so refer to our bi-weekly benchmarks for the most up-to-date pricing.
Other features and support
To wrap this up there are other edge cases that can be important when evaluating web scraping APIs like additional features, support, and documentation.
For features, AI data parsing is a popular one. Unfortunately, it's not offered by all services and each implementation varies greatly so your experience might vary.
Full browser automation features can be critical for scraping more complex web applications that require user inputs like clicks and form submissions. This feature is also great for developers new to web scraping as it requires no reverse engineering knowledge.
For support, most services offer live chat and extensive documentation as well as an interactive API player for testing. Live chat is incredibly valuable as things tend to change and move quickly in the web scraping field.
For our full coverage of all features see our services overview directory.
Conclusion
So the best web scraping API can clearly be found through real evaluation techniques that measure success rate, speed, and price.
Smaller companies might want to target the price metric more while bigger operations should focus on success rate and reliability.
Either way, each evaluation should be done for each individual web scraping target as scraping conditions vary greatly for each website. For this, see Scrapeway's bi-weekly benchmarks for the most up-to-date information every two weeks!
Get benchmark reports, industry insights, and scraping guides — once per week.